Google Spanner : The Future Of NoSQL
Quite often, while working with Hbase, I used to feel how cool it would be to have a database that can replicate my data to datacenters across the world consistently. So that I can take the pleasure of global availability and geographic locality. And also which will save my data even in case of some catastrophe or natural disaster. Which supports general-purpose transactions, and provides a SQL-based query language. And which has features of an SQL database as well. But it was only untill recently I found out that it is not an imagination anymore.
I was sitting with a senior+friend of mine at a Cafe Coffee Day nearby and having a casual chat on BigData stuff. During the discussion he told me about something called as SPANNER.
(You might be wondering, why the heck I have emphasized on the word spanner so much. Believe me, you will do the same after reading this post).
After that meeting I almost forgot about that incident. Out of the blue, the word spanner flashed back to my mind 2 days ago and I started googling about spanner and the search led me to this Google research page, which just blew my mind. Google has already been working extensively on something,which they call as Spanner.
Spanner is a scalable, globally-distributed database designed, built, and deployed at Google. At the highest level of abstraction, it is a database that shards data across many sets of Paxos state machines in datacenters spread all over the world. Replication is used for global availability and geographic locality; clients automatically failover between replicas. Spanner automatically reshards data across machines as the amount of data or the number of servers changes, and it automatically migrates data across machines (even across datacenters) to balance load and in response to failures. Spanner is designed to scale up to millions of machines across hundreds of datacenters and trillions of rows. Applications can use Spanner for high availability,even in the face of wide-area natural disasters, by replicating their data within or even across continents.
We can think of Spanner as globally-distributed database that may spread across the continents covering the planet. Spanner provides several very interesting features :
1 : The replication configurations for data can be controlled dynamically by the applications in a fine grained manner.
2 : It gives us the ability to control which datacenters contain which data.
3 : To control read latency it gives application the ability to decide how far data is from its users etc etc.
But there are 2 things which really stand out : externally consistent reads and writes, and globally consistent reads across the database at a timestamp. Both these things are really difficult to implement in a distributed database. These features enable Spanner to support consistent backups, consistent MapReduce executions, and atomic schema updates, all at global scale, and even in the presence of ongoing transactions.
Few words on the Structure :
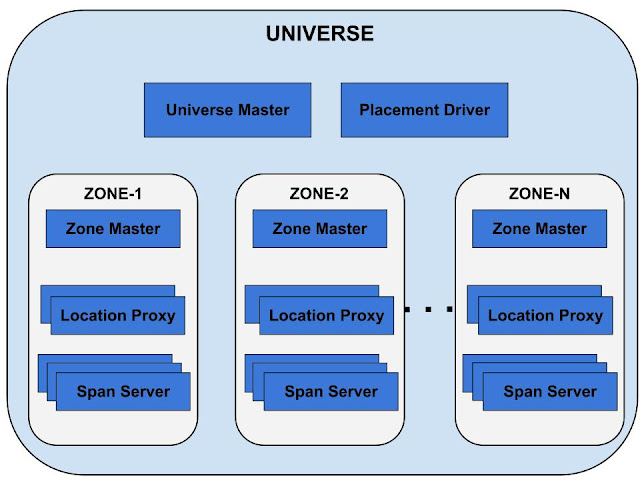
A Spanner deployment is called a universe. Spanner is organized as a set of zones, where each zone is somewhat like a Bigtable deployment. Zones can be added to or removed from a running system as new datacenters are brought into service and old ones are turned off. The set of zones is also the set of locations across which data can be replicated. The figure drawn below shows the Spanner server organization :
I was sitting with a senior+friend of mine at a Cafe Coffee Day nearby and having a casual chat on BigData stuff. During the discussion he told me about something called as SPANNER.
(You might be wondering, why the heck I have emphasized on the word spanner so much. Believe me, you will do the same after reading this post).
After that meeting I almost forgot about that incident. Out of the blue, the word spanner flashed back to my mind 2 days ago and I started googling about spanner and the search led me to this Google research page, which just blew my mind. Google has already been working extensively on something,which they call as Spanner.
Spanner is a scalable, globally-distributed database designed, built, and deployed at Google. At the highest level of abstraction, it is a database that shards data across many sets of Paxos state machines in datacenters spread all over the world. Replication is used for global availability and geographic locality; clients automatically failover between replicas. Spanner automatically reshards data across machines as the amount of data or the number of servers changes, and it automatically migrates data across machines (even across datacenters) to balance load and in response to failures. Spanner is designed to scale up to millions of machines across hundreds of datacenters and trillions of rows. Applications can use Spanner for high availability,even in the face of wide-area natural disasters, by replicating their data within or even across continents.
We can think of Spanner as globally-distributed database that may spread across the continents covering the planet. Spanner provides several very interesting features :
1 : The replication configurations for data can be controlled dynamically by the applications in a fine grained manner.
2 : It gives us the ability to control which datacenters contain which data.
3 : To control read latency it gives application the ability to decide how far data is from its users etc etc.
But there are 2 things which really stand out : externally consistent reads and writes, and globally consistent reads across the database at a timestamp. Both these things are really difficult to implement in a distributed database. These features enable Spanner to support consistent backups, consistent MapReduce executions, and atomic schema updates, all at global scale, and even in the presence of ongoing transactions.
Few words on the Structure :
A Spanner deployment is called a universe. Spanner is organized as a set of zones, where each zone is somewhat like a Bigtable deployment. Zones can be added to or removed from a running system as new datacenters are brought into service and old ones are turned off. The set of zones is also the set of locations across which data can be replicated. The figure drawn below shows the Spanner server organization :

A zone has one zonemaster and between one hundred and several thousand spanservers. The former assigns data to spanservers; the latter serve data to clients. The per-zone location proxies are used by clients to locate the spanservers assigned to serve their data. The universe master and the placement driver are currently singletons. The universe master is primarily a console that displays status information about all the zones for interactive debugging. The placement driver handles automated movement of data across zones on the timescale of minutes. The placement driver periodically communicates with the spanservers to find data that needs to be moved, either to meet updated replication constraints or to balance load.
For a detailed info you can download the original paper (used as the reference) from here.
I hope you enjoyed reading this post and knowing about Spanner as much as I did. Don't forget to provide me your comments and/or suggestions. Thank you.
Comments
Post a Comment